

引言
在数据科学和机器学习领域,图库是一个重要的资源,它为研究人员提供了大量的图像数据,用于训练和测试模型。随着技术的进步,图库也在不断更新,以满足更高精度和更复杂任务的需求。新版49号图库(以下简称“新图库”)就是这样一个例子,它不仅包含了大量的图像数据,还深入解释了数据的定义和结构,特别是Mixed43.275这一部分,这对于理解数据集的复杂性和多样性至关重要。
新图库概览
新图库是一个包含多种图像类别和场景的数据集,它旨在提供更加全面和平衡的数据,以支持各种视觉识别任务。与传统图库相比,新图库在数据量、多样性和标签准确性方面都有显著提升。
Mixed43.275的定义
Mixed43.275是新图库中的一个子集,它包含了43个不同的类别,每个类别有275张图像。这个子集的设计目的是为了提供更加混合和平衡的数据,以便于训练模型在不同类别之间进行有效的区分和识别。
数据的多样性
Mixed43.275中的图像覆盖了从自然景观到人造物体的广泛类别,包括动物、植物、交通工具、日常用品等。这种多样性是数据集设计的关键特点之一,因为它模拟了现实世界中视觉识别任务的复杂性。
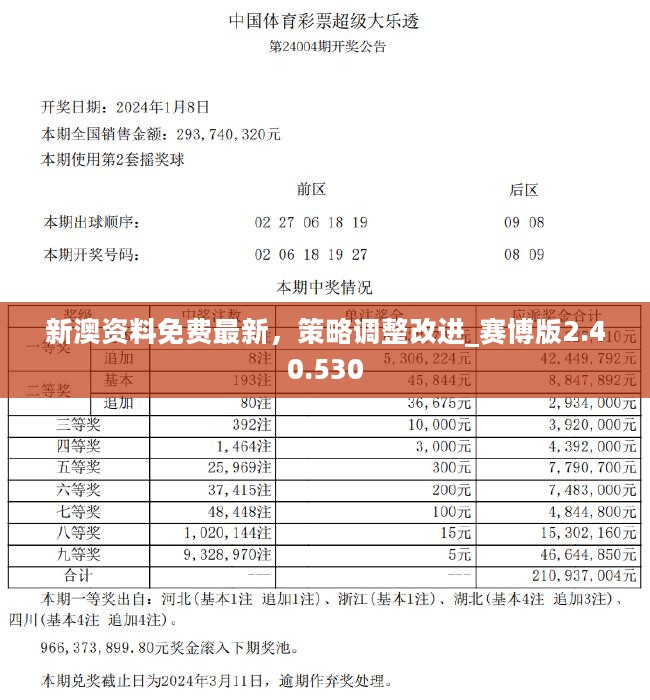
数据的平衡性
在Mixed43.275中,每个类别的图像数量都是相同的,这种平衡性确保了模型在训练过程中不会偏向于某些类别。这对于提高模型的泛化能力至关重要,因为它需要在所有类别上都表现良好。
数据标注的准确性
新图库中的图像都经过了精确的标注,每个图像都有一个或多个与之对应的标签。这种准确的标注是机器学习模型训练的基础,它直接影响到模型的识别能力和性能。
深入数据解释的重要性
深入理解数据集的结构和定义对于研究人员来说至关重要。它不仅有助于选择合适的模型和训练策略,还能帮助研究人员更好地评估模型的性能。对于Mixed43.275这样的子集,深入的数据解释可以帮助研究人员理解不同类别之间的关系,以及如何在模型中有效地处理这些关系。
Mixed43.275的应用场景
Mixed43.275由于其多样性和平衡性,可以应用于多种场景,包括但不限于图像分类、目标检测、场景识别等。这些应用场景都需要模型能够准确地识别和区分不同的图像类别。

数据预处理
在使用Mixed43.275进行模型训练之前,通常需要进行数据预处理。这包括图像的缩放、裁剪、归一化等操作,以确保数据的一致性和模型的输入要求。预处理是提高模型性能的关键步骤之一。
模型训练与验证
在新图库中,Mixed43.275可以作为训练和验证数据集。研究人员可以利用这个子集来训练模型,并在独立的测试集上验证模型的性能。这种分离有助于评估模型的泛化能力,确保它在未见过的数据上也能表现良好。
性能评估指标
评估模型在Mixed43.275上的性能时,常用的指标包括准确率、召回率、F1分数等。这些指标可以帮助研究人员全面了解模型在不同类别上的表现,以及模型的整体性能。
挑战与机遇
尽管Mixed43.275提供了丰富的数据和深入的数据解释,但研究人员在利用这些数据时仍面临挑战。例如,如何处理类别不平衡、如何提高模型的鲁棒性等。同时,这些挑战也带来了机遇,促使研究人员开发更先进的算法和技术。

结论
新版49号图库,尤其是Mixed43.275子集,为视觉识别任务提供了一个强大的数据资源。深入理解这些数据的定义和结构,可以帮助研究人员更有效地利用这些数据,推动机器学习和计算机视觉领域的发展。




 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号